S&P2019
论文信息
标题:Comprehensive Privacy Analysis of Deep Learning
作者:Milad Nasr, Reza Shokri, Amir Houmansadr
出处:S&P
年份:2019
概述
本文对深度学习模型上的白盒隐私推理攻击进行了详细的分析。本文针对被动和主动推理攻击这,在独立和联合设置下设计攻击,并假设对手具有不同的先验知识,证明了即使是通用化的模型也极易受到白盒成员推理攻击的影响。
背景
应用场景
许多应用程序和服务在大范围(且可能敏感)的用户数据上使用深度学习算法,其中包括用户语音,图像以及医疗,财务,社交和位置数据点。
问题陈述
提出问题:深度学习算法对于单个训练数据样本的信息泄露量是多少?
定义对于目标训练数据记录的一个模型的敏感隐私泄露为:攻击者可以推理出的关于数据记录的信息,并且不能由未使用该训练数据的相似模型推理得出。
价值
论文贡献
本文提供了一个使用白盒成员推理攻击进行深度神经网络隐私分析的综合框架,并且从以下方面对该框架进行了评估:独立/联合设置;攻击完美训练/进行了微调的模型;无监督攻击;被动/主动推理攻击。
证明了即使是通用化的模型也极易受到白盒成员推理攻击的影响;即使使用预先训练的最先进的目标模型,攻击仍然有效。
论文弱点
本文只针对论文中提出的攻击方法进行了详细描述和评估,通过实验结果可以看到攻击的准确率几乎都在70%及以上。本文在文章最后提到了差分隐私,说差分隐私是一个强大的防御方法,但是又说本文的攻击者可以通过观察参数来推理大量的私人信息,并不清楚差分隐私能不能防御本文的攻击方法。
方案
技术依据
深度神经网络会记住有关其训练数据的信息,因此容易受到推理攻击。并且在白盒背景下,攻击者可以获取模型(包括模型参数),进而可以计算每一层的输出,梯度还有损失。
本文利用随机梯度下降(SGD)算法的隐私漏洞来设计白盒推理攻击。因为为了最大程度的减少模型的预期损失,SGD算法会在整个训练数据集的损失梯度趋于零的方向上反复更新模型参数。因此,每个训练数据样本都会在模型参数上的损失函数的局部梯度上留下明显的足迹。
攻击者利用这些可以获取的信息进行攻击,并且评估在各种场景下的训练数据泄露程度。
方案框架
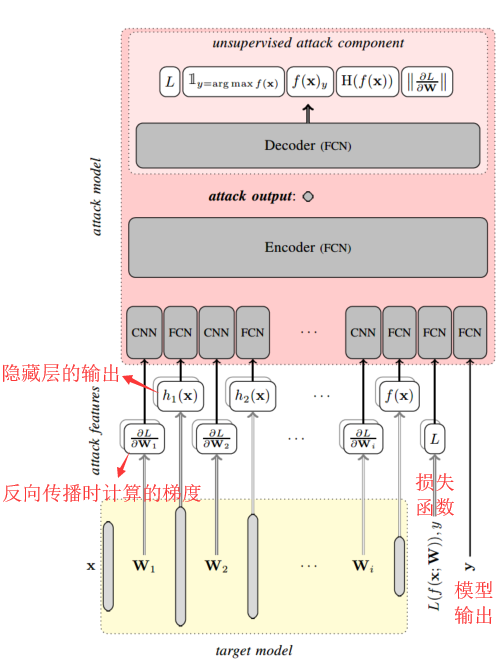
给定目标数据(x,y),攻击者在目标输入x上运行目标模型f,计算所有隐藏层、模型输出和损失函数。攻击者还会在反向传播时计算相对于每个层的参数的损耗梯度。这些计算构成了推理攻击的输入特征。
攻击模型由卷积神经网络(CNN)和全连接网络组成(FCN),攻击者对每个攻击特征观察多次,并在将它们传递到相应的攻击组件之前对其进行堆叠。CNN和FCN组件的输出附加到一起,并且此向量传递到完全连接的编码器,利用编码器和多个隐藏层来组合所有攻击特征提取组件的输出。编码器的输出是单个分数,即攻击的输出,预测了输入数据的隶属概率。
评估
评价标准
Attack accuracy:对于一个未知的数据点的正确的成员资格预测的分数
True/False positive:True positive代表本来是成员,分类成成员;False positive代表本来不是成员,分类成成员
Prediction uncertainty:使用对于给定输入的预测向量的归一化熵来计算
评估结果
场景1:独立学习;攻击完美训练的模型;CIFAR100
证明了模型最后一层的输出泄露的成员信息最多;相对于模型输出来说,梯度会泄露更多的成员信息;相较于模型的其它层,最后一层的梯度泄露更多的成员信息;训练集大小、成员和非成员的比例将影响攻击准确性;成员的梯度范式随着训练周期下降;拥有高预测不准确性的类会泄露更多成员信息。
场景2:独立学习;无监督攻击;CIFAR100,Texas100,Purchase100
从实验结果来看,本文的攻击在当前场景下提供了很高的攻击准确度
场景3:独立学习;攻击微调(为了更好的训练准确度)模型
攻击者可以区分成员(分别在训练模型的数据集里和训练微调模型的数据集里)和非成员,还可以区分两个数据集的成员。
场景4:联邦学习;被动推理攻击(默默观察)
被动全局攻击者(参数聚合器)。对于CIFAR100数据集,达到了一个较高的准确度,但是对于Texas100和Purchase100,与独立学习相比准确度下降。
被动本地攻击者(学习参与者)。相较于全局攻击,准确度低,因为只能观察聚合之后的参数更新,限制了信息泄露。
场景5:联邦学习;主动推理攻击(会攻击性的修改参数更新)
梯度上升攻击:相较被动全局攻击,主动全局攻击获得更高的准确度。本地攻击的准确度低于全局攻击。
孤立攻击:攻击者隔离目标参与者和其学习进程。隔离之后目标参与者的模型不会进行聚合,并且存储了很多信息。
仅仅运用孤立,攻击准确度上升。将梯度上升和孤立合起来运用,攻击准确度进一步提高。