USNIX2020
基本信息
论文来源
Klas Leino and Matt Fredrikson. “Stolen Memories: Leveraging Model Memorization for Calibrated White-Box Membership Inference’’ Proceedings of the 29th USENIX Security Symposium, 2020.
概述
本文针对白盒设置下的成员推理攻击进行了讨论,首先在线性模型中运用贝叶斯优化进行攻击,进而将攻击思路推广到深度模型中,并提出对攻击的精度进行校准。最后本文对攻击方法进行了防御评估。
论文要点
背景
机器学习的许多应用涉及敏感个人数据的收集和处理,这引起了我们对于隐私的担忧。特别是,将机器学习算法应用于私人训练数据时,生成的模型可能会通过其行为或表示,无意间泄露有关该数据的信息。成员推理攻击旨在确定在用于构建模型的训练集中是否存在给定的数据点。迄今为止,大多数成员推理攻击都遵循影子模型方法,Nasr等人将该方法扩展到白盒设置,但是他们发现将影子模型方法简单扩展到白盒设置不会产生有效的攻击。因此,本文基于这个背景,研究并提出一种有效的白盒成员推理攻击。
问题陈述
目前的成员推理攻击方法大多是在黑盒设置下,虽然Nasr等人从目标模型获得激活和梯度信息,并将其作为攻击模型的功能,以此将攻击扩展到白盒设置中。但是他们发现这种简单扩展不会产生有效的攻击,因此他们假设对手已经知道目标模型的训练数据的很大一部分,但这种白盒攻击偏离了大多数针对成员推理的工作所共有的威胁模型。
因此本文重新审视了白盒成员推理的问题,提出了一种有效的白盒成员推理攻击,这种攻击无需访问目标模型的任何训练数据即可进行操作。并且,本文的分析揭示了对模型中过度拟合如何发生的更深入的了解,即训练数据中存在的特有特征(仅对训练数据具有预测性,而对采样分布没有预测性)通常在训练过程中被编码在模型中。
威胁模型
本文展示了如何明确识别深度网络中的记忆,并利用它来进行成员推理。成员信息通过目标模型的特有功能泄漏,而训练数据中分布的特征与普通人群中分布的特征不同,这些特征提供了支持或反对成员资格的证据。
本文发现可以对攻击进行校准,以增强对肯定推理的信心。
本文评估了针对本文攻击方法的常用防御的实用性。
主要贡献
- 本文展示了如何明确识别深度网络中的记忆,并利用它来进行成员推理。成员信息通过目标模型的特有功能泄漏,而训练数据中分布的特征与普通人群中分布的特征不同,这些特征提供了支持或反对成员资格的证据。
- 本文发现可以对攻击进行校准,以增强对肯定推理的信心。
- 本文评估了针对本文攻击方法的常用防御的实用性。
方案
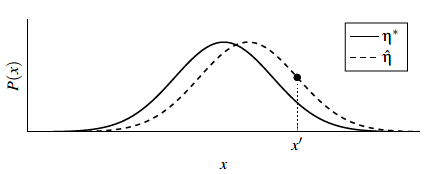
图1展示了两个高斯分布$\eta^{}$和$\hat{\eta}$的示例,其中$\eta^{}$表示普通人群、$\hat{\eta}$表示训练集。如果$x^{\prime}$满足公式1,则我们认为$x^{\prime}$更可能从$\hat{\eta}$中提取,而不是$\eta^{}$。因此我们可以创建一个分类器来判断$x^{\prime}$是从哪个分布里提取的。
$$Pr_{\eta^{*}}\left[x^{\prime}\right]<Pr_{\hat{\eta}}\left[x^{\prime}\right]$$
贝叶斯最优成员推理bayes-wb
攻击假设:
- 假设数据符合高斯分布,并且满足朴素贝叶斯假设
- 使用经验均值和协方差将训练集建模为高斯分布
- 假设目标模型是线性模型
由上述思想,攻击者可以利用朴素贝叶斯假设进行成员推理攻击,也就是说,攻击者可以将给定标记的$x$的观测概率写作独立观测$x$的每个特征的概率的乘积。公式2给出成员资格的贝叶斯最优预测器。其中攻击模型$m^{y}(x)$被定义为,给出点$(x,y)$属于训练集$S$的概率。
$$m^{y}(x)=\mathcal{\delta}\left(w^{y T} x+b^{y}\right)$$
其中 $\qquad w^{y}=\frac{\hat{\mu}{y}-\mu{y}^{}}{\sigma^{2}} \qquad b^{y}=\sum_{j} \frac{\mu_{y j}^{ 2}-\hat{\mu}{y j}^{2}}{2 \sigma{j}^{2}}$
在现实中,攻击者并不能准确的知道分布$\hat{\mathcal{D}}$和$\mathcal{D}^{}$的参数,但是目标模型$\hat{g}$学习到的权重会对$\hat{\mathcal{D}}$更加敏感,因此攻击者可以使用权重来对有关$\hat{\mathcal{D}}$和$\mathcal{D}^{}$的差异的有用信息进行编码。具体攻击流程如下:
- 在辅助数据上训练代理模型。
- 将代理模型的权重与目标模型的权重进行比较,以创建攻击模型。
- 将样本点$(x,y)$输入攻击模型,模型会给出判断结果。因为在目标模型中使用的特征与在代理模型中使用的特征不同,因此它可以用于确定成员资格。
任意分布成员推理general-wb
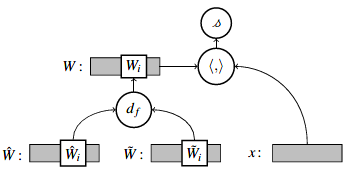
bayes-wb攻击通过测量目标模型的权重与代理模型所近似的真实分布的理想权重之间的某种位移来加权成员预测。因此本文定义了一个位移函数$d_f$,将其逐元素应用于模型的权重,这样可以将bayes-wb应用到任意分布中。在高斯朴素贝叶斯假设下,逐元素减法(即$d_f (x,y)=x-y$)是进行成员推理的最佳选择,但对于其他分布而言,不同的位移函数可能更合适。
图2显示了general-wb的模型,将学习到的位移函数$d_f$逐元素应用于目标和代理模型的权重,以生成攻击模型权重$W$,同时也应用于目标和代理模型的偏置,以生成攻击模型的偏置$b$。然后,使用$W$和$x$的内积进行成员预测。
深度模型中的成员推理
我们可以将上述思想应用于深度网络的各个层中,但是在这之前我们需要将网络分解为两个函数,即$f=g \circ h$。其中,$h$计算特征,$g$使用这些特征进行分类。
对于网络顶层,$g$是一个线性模型,可以直接应用上述算法。对于网络中低层,$g$不再是线性的,但是我们可以通过局部线性近似来将$g$近似为线性的,然后应用上述算法,如图3。
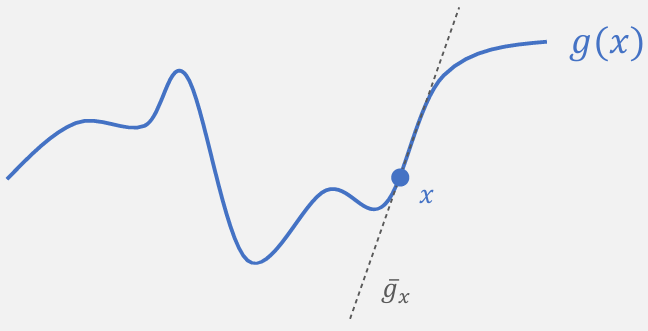
由于模型的内部表示在各层之间并不是独立的,因此我们不能简单地将每一层的近似权重串联起来,并将其视为对单个模型的攻击。相对的,我们可以使用一个元模型,该模型学习如何组合各个分层攻击的逻辑输出。
评估
评价指标
攻击的准确度是指$\mathcal{A}$的预测等于$b$的概率。由于攻击者随机猜测可以达到50%的准确度,因此我们通常选择描述攻击的优势,即公式2给出的。优势将准确度缩放到基线的50%,以得出介于-1和1的值。
$$advantage(\mathcal{A})=2Pr[\mathcal{A}((x, y), aux(\hat{g}))=b]-1$$
如果对手可以自信地识别出任何数据点,就会发生侵犯隐私的行为,这样造成的威胁要比攻击者以较低的信心识别每个训练人员所造成的威胁大得多。因此,我们还将精度(等式3)视为攻击者的关键目标。为了使攻击者能够得出可靠的推论,精度必须明显大于1/2。如果没有点被预测为成员,则将精度定义为1/2。
$$precision(\mathcal{A})=Pr[b=1 \mid \mathcal{A}((x, y), aux(\hat{g}))=1]$$
最后,召回率(等式4)也是一项评估指标。但是,我们对这个指标的重视程度较低,因为如果无法在任何点上返回可信的推断,则具有较高召回率的攻击在实践中不一定有效。
$$recall(\mathcal{A})=Pr[\mathcal{A}((x, y), aux(\hat{g}))=1 \mid b=1]$$
数据集
本文针对合成数据和源自真实数据的九个分类数据集进行了实验。通常,从医学和金融等领域选择数据集,本文为了便于与以前的工作进行比较,还包括了三个常见的图像数据集(MNIST,CIFAR10和CIFAR100)。
合成数据集具有10个类别,75个要素,数据记录量分别为400、800或1600,每类具有相等数量的记录。合成数据的特征是从多元高斯分布中随机抽取的。
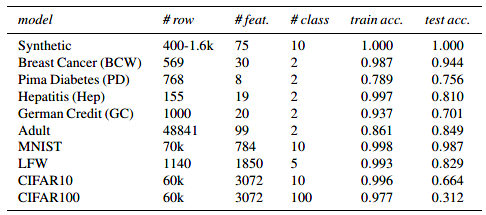
分类数据集包含,成年人,Pima糖尿病;威斯康星州乳腺癌,肝炎,德国信贷,LFW;MNIST,CIFAR10和CIFAR100。图4显示了每个数据集的特征。
评估结果
在评估每种攻击时,本文将数据随机分为三个不相交的组:训练,测试和保持。训练组和测试组各占实例总数的四分之一,而保留组则占实例总数的剩余一半。目标模型在训练组上进行了训练,而攻击者只允许使用保留组,在训练组(成员)和测试组(非成员)上评估了攻击模型的预测,每个实验在数据拆分的不同随机采样上重复10次,并取平均值。
在整个评估过程中,我们评估了四种不同的攻击:天真,bayes-wb,general-wb和shadow-bb。天真的攻击是指,当且仅当x正确分类时,攻击模型才能预测实例x是训练集的成员。shadow-bb是指黑盒阴影模型攻击。
我们可以将无所不知的攻击视为对高斯朴素贝叶斯数据进行白盒攻击的预期准确性的上限,因为这是真正的贝叶斯最优攻击。本文的攻击平均获得了全知攻击的84%的优势,这表明代理模型能够根据需要大致捕获总体分布,以检测目标模型对特征的特质使用。
当代表位移函数的神经网络被赋予足够的能力来重现bayes-wb攻击时,general-wb平均恢复了bayes-wb攻击优势的94%。通过检查位移网络的权重,我们发现general-wb几乎精确地学习了逐元素减法,这表明了其学习最佳位移函数的潜力。如果容量过大,则general-wb攻击的性能仅会稍差一些,平均可达到最低general-wb攻击优势的92%(Bayes-wb的86%),这表明General-wb不太容易过度拟合。
当然,我们发现这种模式对于现实世界的数据集也同样有效。在攻击真实数据集Adult时,我们观察到,随着更多数据可用于训练,攻击的优势逐渐减弱,但这个优势在整个数据集上变化得很小(\textless4%)。这可能表明Adult数据集足够大,可以通过标准训练获得的中等大小的MLP模型来防止任何重大的信息泄漏。
评论
扩展阅读
Milad Nasr, Reza Shokri, and Amir Houmansadr. Comprehensive privacy analysis of deep learning: Stand-alone and federated learning under passive and active white-box inference attacks. CoRR, abs/1812.00910, 2018.
Reza Shokri, Marco Stronati, and Vitaly Shmatikov. Membership inference attacks against machine learning models. CoRR, abs/1610.05820, 2016.
启示
相对于先前的工作,这篇论文改进的地方是用到了模型内部的信息,可以让攻击者对自己推理结果更加有信心,但他仍然有影子模型的思想在里面。本文中提到每个类别可能具有不同的均值,因此必须使用单独的标准来将它们区分开,但是作者直接假定为对手提供了真实的类别标签,所以没有在这个地方多做说明,而我认为我可以在我的工作中利用这一点,因为我想要推理出来的是一个类。